|
"
0
C
F
G
H
K
L
N
P
S
T
W
Z
А
Б
В
Г
Д
Е
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Э
Ю
Я
ОЦЕНКА СТАТИСТИЧЕСКАЯЗначение ОЦЕНКА СТАТИСТИЧЕСКАЯ в математической энциклопедии: - функция от случайных величин, применяемая для оценки неизвестных параметров теоретич. распределения вероятностей. Методы теории О. с. служат основой современной теории ошибок; обычно в качестве неизвестных параметров выступают измеряемые физич. постоянные, а в качестве случайных величин - результаты непосредственных измерений, подверженные случайным ошибкам. Напр., если О. с. как функция от случайных величин чаще всего задается теми или иными формулами, выбор к-рых определяется требованиями практики. При этом различают оценки точечные и оценки интервальные. Точечные оценки. Точечной оценкой наз. такая О. с., значение к-рой представимо геометрически в виде точки в том же пространстве, что и значения неизвестных параметров (размерность пространства равна числу оцениваемых параметров). Именно точечные О. с. и используются как приближенные значения для неизвестных физич. величин. В дальнейшем для простоты предполагается, что оценке подлежит один единственный параметр; в этом случае точечная О. с. представляет собой функцию от результатов наблюдений, принимающую числовые значения. Точечную О. с. наз. несмещенной, если ее математич. ожидание совпадает с оцениваемой величиной, т. е. если О. с. лишена систематич. ошибки. Среднее арифметическое (1) - несмещенная О. с. для математич. ожидания одинаково распределенных случайных величин Xi (не обязательно нормальных). В то же время выборочная дисперсия является смещенной О. с. для дисперсии См. также Несмещенная оценка. За меру точности несмещенной О. с. а для параметра ачаще всего принимают дисперсию Da. О. с. с наименьшей дисперсией наз. наилучшей. В приведенном примере среднее арифметическое (1) - наилучшая О. с. Однако если распределение вероятностей случайных величин Xi отлично от нормального, то О. с. (1) может и не быть наилучшей. Напр., если результаты наблюдений Х i распределены равномерно в интервале (b, с), то наилучшей О. с. для математич. ожидания а=(b+с)/2 будет полусумма крайних значений В качестве характеристики для сравнения точности различных О. с. применяют эффективность - отношение дисперсий наилучшей оценки и данной несмещенной оценки. Напр., если результаты наблюдений Х i распределены равномерно, то дисперсии оценок (1) и (3) выражаются формулами Так как оценка (3) наилучшая, то эффективность оценки (1) в данном случае есть При большом количестве наблюдений побычно требуют, чтобы выбранная О. с. стремилась по вероятности к истинному значению параметра а, т. е. чтобы для всякого e > 0 такие О. с. наз. состоятельными (пример состоятельной О. с,- любая несмещенная оценка, дисперсия к-рой при Напр., если и, кроме того, Фундаментальное значение для теории О. с. и ее приложений имеет тот факт, что квадратичное отклонение О. с. для параметра аограничено снизу нек-рой величиной (этой величиной Р. Фишер (R. Fischer) предложил характеризовать количество информации относительно неизвестного параметра a, содержащийся в результатах наблюдений). Напр., если где Функцию b(а) наз. смещением, а величину, обратную правой части неравенства (5), наз. количеством информации (по Фишеру) относительно функции g(a), содержащейся в результате наблюдений. В частности, если а - несмещенная О. с. параметра а, то , и причем количество информации nIa в этом случае пропорционально количеству наблюдений (функцию I(а).наз. количеством информации, содержащейся в одном наблюдении). Основные условия, при к-рых справедливы неравенства (5) и (6), - гладкость оценки акак функции от Xi, а также независимость от параметра амножества тех точек х, где р( х, а)=0. Последнее условие не выполняется, напр., в случае равномерного распределения, и поэтому дисперсия О. с. (3) не удовлетворяет неравенству (6) [согласно (4) эта дисперсия есть величина порядка n-2, в то время как по неравенству (6) она не может иметь порядок малости выше, чем п -1]. Неравенства (5) и (6) справедливы и для дискретно распределенных случайных величин Xi нужно лишь в определении информации I(а).плотность р(х; а).заменить вероятностью события {Х=х}. Если дисперсия несмещенной О. с. a* для параметра асовпадает с правой частью неравенства (6), то Особенно плодотворным информационный подход к теории О. с. сказывается тогда, когда плотность (в дискретном случае - вероятность) совместного распределения случайных величин Один из наиболее распространенных методов нахождения точечных О. с.- моментов метод. Согласно этому методу, теоретич. распределению, зависящему от неизвестных параметров, ставят в соответствие дискретное выборочное распределение, к-рое определяется результатами наблюдений Xi и представляет собой распределение вероятностей воображаемой случайной величины, принимающей значения Другой метод нахождения О. с., более совершенный с теоретич. точки зрения,- максимального правдоподобия метод, или наибольшего правдоподобия метод. Согласно этому методу, рассматривают функцию правдоподобия L(а), к-рая представляет собой функцию неизвестного параметра аи получается в результате замены в плотности совместного распределения (если Xi распределены дискретно, то в определении функции правдоподобия Lследует плотности заменить вероятностями событий Основное достоинство О. с. максимального правдоподобия заключается в том, что при нек-рых общих условиях эти оценки состоятельны, асимптотически эффективны и распределены приближенно нормально. Перечисленные свойства означают, что если a есть О. с. максимального правдоподобия, то при (если Xнезависимы, то Преимущества О. с. максимального правдоподобия оправдывают вычислительную работу по отысканию максимума функции L(или l). В нек-рых случаях вычислительная работа существенно сокращается благодаря следующим свойствам: во-первых, если a* - такая О. с., для к-рой неравенство (6) обращается в равенство, то О. с. максимального правдоподобия единственна и совпадает с a*, во-вторых, если существует достаточная статистика Z, то О. с. максимального правдоподобия есть функция Z. Пусть, напр., поэтому Координаты а= а 0 и s= s0 точки максимума функции I( а,s).удовлетворяют системе уравнений Таким образом, Еще один пример, в к-ром Эта плотность удовлетворительно описывает распределение одной из координат частиц, достигших плоского экрана и вылетевших из точки, расположенной вне экрана (a - координата проекции источника на экран- предполагается неизвестной). Для указанного распределения математич. ожидание не существует, т. к. соответствующий интеграл расходится. Поэтому отыскание О. с. для аметодом моментов невозможно. Формальное применение в качестве О. с. среднего арифметического (1) лишено смысла, т. к. В то же время поэтому В качестве первого приближения выбирают a0=u и далее решают это уравнение последовательными приближениями по формуле См. также Точечная оценка. Интервальные оценки. Интервальной оценкой наз. такая О. с., к-рая геометрически представима в виде множества точек, принадлежащих пространству параметров. Интервальную О. с. можно рассматривать как множество точечных О. с. Это множество зависит от результатов наблюдений и, следовательно, оно случайно; поэтому каждой интервальной О. с. ставится в соответствие вероятность, в к-рой эта оценка "накроет" неизвестную параметрич. точку. Такая вероятность, вообще говоря, зависит от неизвестных параметров; поэтому в качестве характеристики достоверности интервальной О. с. принимают коэффициент доверия - наименьшее возможное значение указанной вероятности. Содержательные стати-стич. выводы позволяют получать лишь те интервальные О. с., коэффициент доверия к-рых близок к единице. Если оценивается один параметр a, то интервальной О. с. обычно является нек-рый интервал (b, g).(т. н. доверительный интервал), конечные точки к-рого (b и g представляют собой функции от результатов наблюдений; коэффициент доверия со в данном случае определяется как нижняя грань вероятности одновременного осуществления двух событий {b < a} и (g > a}, вычисляемая по всем возможным значениям параметра a: Если середину такого интервала Если распределение случайных величин Xi зависит только от одного неизвестного параметра а, то построение доверительного интервала обычно осуществляется с помощью какой-либо точечной О. с. а. Для большинства практически интересных случаев функция распределения [для непрерывных распределений где х - корень уравнения Если Как уже отмечалось выше, если и, следовательно, она зависит не только от a, но также и от s. В то же время распределение т. н. отношения Стьюдента не зависит ни от a, ни от s, причем где постоянная соответствует коэффициент доверия Распределение оценки s2 зависит лишь от s2, причем функция распределения О. с. s2 аадается формулой где постоянная Dn-1 определяется условием Так как с ростом s вероятность соответствует коэффициент доверия w. Отсюда, в частности, следует, что доверительный интервал для относительной ошибки задается неравенствами Подробные таблицы функций распределения Стьюдента До сих пор предполагалось, что функция распределения результатов наблюдений известна с точностью до значений нескольких параметров. Однако в приложениях часто встречается случай, когда вид функции распределения неизвестен. В этой обстановке для оценки параметров могут оказаться полезными т. н. непараметрические методы статистики (т. е. такие методы, к-рые не зависят от исходного распределения вероятностей). Пусть, напр., требуется оценить медиану ттеоретич. непрерывного распределения независимых случайных величин X1, Х 2,..., Х п (для симметричных распределений медиана совпадает с математич. ожиданием, если, конечно, оно существует). Пусть Y1 Таким образом, Выше отмечалось, что выборочное распределение - точечная О. с. для неизвестного теоретич. распределения. Более того, функция Выборочного распределения Fn(x).- несмещенная О. с. для функции теоретич. распределения F(x). При этом, как показал А. Н. Колмогоров, распределение статистики не зависит от неизвестного теоретич. распределения и при Статистические оценки в теории ошибок. Теория ошибок - раздел математич: статистики, посвященный численному определению неизвестных величин по результатам измерений. В силу случайного характера ошибок измерений и, быть может, случайной природы самого изучаемого явления не все такие результаты равноправны: при повторных измерениях нек-рые из них встречаются чаще, другие - реже. В основе теории ошибок лежит математич. модель, согласно к-рой до опыта совокупность всех мыслимых результатов измерения трактуется как множество значений нек-рой случайной величины. Поэтому важную роль приобретает теория О. с. Выводы теории ошибок носят статистич. характер. Смысл и содержание таких выводов (как, впрочем, и выводов теории О. <с.) проявляются лишь в свете закона больших чисел (пример такого подхода - статистич. толкование смысла коэффициента доверия, указанного выше). Полагая результат измерения Xслучайной величиной, различают три основных типа ошибок измерений: систематические, случайные и грубые (качественные описания таких ошибок даны в ст. Ошибок теория). При этом ошибкой измерения неизвестной величины аназ. разность X-а, математич. ожидание этой разности E( Х-а)=b наз. систематической ошибкой (если b=0, то говорят, что измерения лишены систематич. ошибок), а разность d=Х- а-b наз. случайной ошибкой где аи b- постоянные, a di - случайные величины. В более общем случае где bi - не зависящие от di случайные величины, к-рые равны нулю с вероятностью, весьма близкой к единице (поэтому всякое другое значение Задача оценки (и устранения) систематич. ошибки обычно выходит за рамки математич. статистики. Исключения составляют т. н. метод эталонов, согласно к-рому для оценки bпроизводят серию измерений известной величины а(в этом методе b - оцениваемая величина и а - известная систематич. ошибка), а также дисперсионный анализ, позволяющий оценивать систематич. расхождения между несколькими сериями измерений. Основная задача теории ошибок - отыскивание О. с. для неизвестной величины аи оценка точности измерений. Если систематич. ошибка устранена (b=0) и наблюдения грубых ошибок не содержат, то согласно (10) Х i=a+di и, значит, в этом случае задача оценки асводится к отысканию в том или ином смысле оптимальной О. с. для математич. ожидания одинаково распределенных случайных величин Xi. Как было показано в предыдущих разделах, вид такой О. с. (точечной или интервальной) существенно зависит от закона распределения случайных ошибок. Если этот закон известен с точностью до нескольких неизвестных параметров, то для оценки, а также для оценки аможно применять, напр., метод максимального правдоподобия; в противном случае следует сначала по результатам наблюдений Х i найти О. с. для неизвестной функции распределения случайных ошибок di ("непараметрическая" интервальная О. с. такой функции указана выше). В практич. работе часто довольствуются двумя О. с. Наличие грубых ошибок усложняет задачу оценки параметра а. Обычно доля наблюдений, в к-рых Простейший пример таких методов - статистпч. выявление одного резко выделяющегося наблюдения, когда подозрительным может оказаться либо Y1=minX1, либо Y п=mахХ i (предполагается, что в равенствах (11) b=0 и закон распределения величин di известен). Для того чтобы выяснить, обосновано ли предположение о наличии одной грубой ошибки, для пары Y1, Yn вычисляют совместную интервальную О. с. (доверительную область), полагая все bi равными нулю. Если эта О. с. "накрывает" точку с координатами (Y1, Yn), то подозрение о наличии грубой ошибки следует считать статистически необоснованным; в противном случае гипотезу о присутствии грубой ошибки надо признать подтвердившейся (при этом обычно забракованное наблюдение отбрасывают, т. к. сколько-нибудь надежно оценить величину грубой ошибки по одному наблюдению статистически не представляется возможным). Пусть, напр., анеизвестно, b=0 и di независимы и распределены одинаково нормально (дисперсия неизвестна). Если все bi=0, то распределение случайной величины но зависит от неизвестных параметров (О. с. Xи где wr (t) -функция распределения Стьюдента, определенная выше. Таким образом, с коэффициентом доверия можно утверждать, что при отсутствии грубой ошибки выполняется неравенство Z< zили, что то же самое, (Погрешность оценки коэффициента доверия по формуле (12) не превышает w2/2.) Поэтому если все результаты измерений Xi лежат в пределах Лит.:[1] Крамер Г., Математические методы статистики, пер. с англ., 2 изд., М., 1975, гл. 33, 34; [2] Дунин - Барконский И. В., Смирнов Н. В., Теория вероятностей и математическая статистика в технике. (Общая часть), М., 1955; [3] Липник Ю. В., Метод наименьших квадратов и основы математико-статистической теории обработки наблюдений, 2 изд., М., 1У62; [4]Ван дер Варден Б. Л., Математическая статистика, пер. с нем., М.. 1960;[5] Арлей Н., Бух К. Р., Введение в теорию вероятностей и математическую статистику, пер. с англ., М., 1951; [0] Колмогоров А. Н., "Изв. АН СССР. Сер. матем.", 1942, т. 6, № 1-2, с. 3-32. Л. Н. Большев. |
|
|
|
 - независимые одинаково нормально распределенные случайные величины (результаты равноточных измерений, подверженных независимым нормально распределенным случайным ошибкам), то в качестве О. с. для неизвестного среднего значения а (приближенного значения измеряемой физич. постоянной) применяется среднее арифметическое
- независимые одинаково нормально распределенные случайные величины (результаты равноточных измерений, подверженных независимым нормально распределенным случайным ошибкам), то в качестве О. с. для неизвестного среднего значения а (приближенного значения измеряемой физич. постоянной) применяется среднее арифметическое 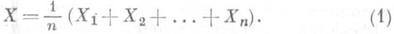
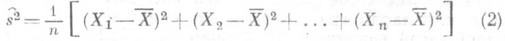
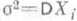 , так как
, так как 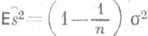 ; в качестве несмещенной О. с. для s2 обычно берут функцию
; в качестве несмещенной О. с. для s2 обычно берут функцию 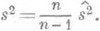
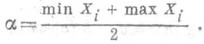 (3)
(3)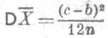 и
и 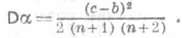 (4)
(4)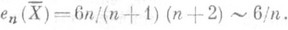
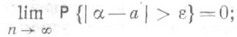
 стремится к нулю; см. также Состоятельная оценка). Поскольку важную роль при этом играет порядок стремления к пределу, то асимптотически наилучшими являются асимптотически эффективные О. с., то есть такие О. с., для к-рых при
стремится к нулю; см. также Состоятельная оценка). Поскольку важную роль при этом играет порядок стремления к пределу, то асимптотически наилучшими являются асимптотически эффективные О. с., то есть такие О. с., для к-рых при 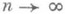

 распределены одинаково нормально, то О. с. (2) представляет собой асимптотически эффективную оценку для неизвестного параметра
распределены одинаково нормально, то О. с. (2) представляет собой асимптотически эффективную оценку для неизвестного параметра 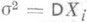 , так как при
, так как при 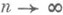 дисперсия оценки
дисперсия оценки 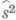 и дисперсия наилучшей оценки
и дисперсия наилучшей оценки 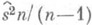 асимптотически эквивалентны:
асимптотически эквивалентны: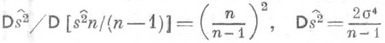
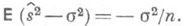
 независимы и одинаково распределены с плотностью вероятности р(х; а).и если
независимы и одинаково распределены с плотностью вероятности р(х; а).и если 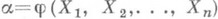 - О. с. для нек-рой функции g(a).от параметра а, то в широком классе случаев
- О. с. для нек-рой функции g(a).от параметра а, то в широком классе случаев 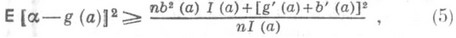
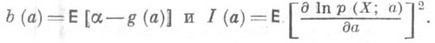
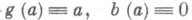
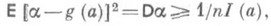 (6)
(6) - наилучшая оценка. Обратное утверждение, вообще говоря, неверно: дисперсия наилучшей О. с. может превышать
- наилучшая оценка. Обратное утверждение, вообще говоря, неверно: дисперсия наилучшей О. с. может превышать 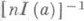 . Однако если
. Однако если  , то дисперсия наилучшей оценки
, то дисперсия наилучшей оценки 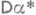 асимптотически эквивалентна правой части (6), т. е.
асимптотически эквивалентна правой части (6), т. е.  . Таким образом, с помощью количества информации (по Фишеру) можно определить асимптотич. эффективность несмещенной О. с. а, полагая
. Таким образом, с помощью количества информации (по Фишеру) можно определить асимптотич. эффективность несмещенной О. с. а, полагая 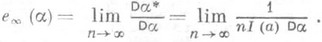 (7)
(7) пред-ставима в виде произведения двух функций h(x1,х 2,...,х п).[у( х 1, х 2,..., х n);а], из к-рых первая не зависит от а, а вторая представляет собой плотность распреде-деления нек-рой случайной величины Z=y(X1, Х 2,..., Х п), наз. достаточной статистикой или исчерпывающей статистикой.
пред-ставима в виде произведения двух функций h(x1,х 2,...,х п).[у( х 1, х 2,..., х n);а], из к-рых первая не зависит от а, а вторая представляет собой плотность распреде-деления нек-рой случайной величины Z=y(X1, Х 2,..., Х п), наз. достаточной статистикой или исчерпывающей статистикой.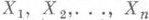 с одинаковыми вероятностями, равными 1/n (выборочное распределение можно рассматривать как точечную О. с. для теоретич. распределения). В качестве О. с. для моментов теоретич. распределения принимают соответствующие моменты выборочного распределения; напр., для математич. ожидания аи дисперсии s2 метод моментов дает следующие О. с.: выборочное среднее (1) и выборочную дисперсию (2). Неизвестные параметры обычно выражаются (точно или приближенно) в виде функций от нескольких моментов теоретич. распределения. Заменяя в этих функциях теоретич. моменты выборочными, получают искомые О. с. Этот метод, часто приводящий на практике к сравнительно простым вычислениям, дает, как правило, О. с. невысокой асимптотической эффективности (см. выше пример оценки математического ожидания равномерного распределения).
с одинаковыми вероятностями, равными 1/n (выборочное распределение можно рассматривать как точечную О. с. для теоретич. распределения). В качестве О. с. для моментов теоретич. распределения принимают соответствующие моменты выборочного распределения; напр., для математич. ожидания аи дисперсии s2 метод моментов дает следующие О. с.: выборочное среднее (1) и выборочную дисперсию (2). Неизвестные параметры обычно выражаются (точно или приближенно) в виде функций от нескольких моментов теоретич. распределения. Заменяя в этих функциях теоретич. моменты выборочными, получают искомые О. с. Этот метод, часто приводящий на практике к сравнительно простым вычислениям, дает, как правило, О. с. невысокой асимптотической эффективности (см. выше пример оценки математического ожидания равномерного распределения). аргументов xi самими случайными величинами Xi; если Xi- независимы и одинаково распределены с плотностью вероятности р(x; а), то
аргументов xi самими случайными величинами Xi; если Xi- независимы и одинаково распределены с плотностью вероятности р(x; а), то 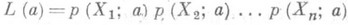
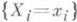 ). В качестве О. с. максимального правдоподобия для неизвестного параметра апринимают такую величину a, для к-рой L(a) достигает наибольшего значения (при этом часто вместо Lрассматривают т. н. логарифмическую функцию правдоподобия
). В качестве О. с. максимального правдоподобия для неизвестного параметра апринимают такую величину a, для к-рой L(a) достигает наибольшего значения (при этом часто вместо Lрассматривают т. н. логарифмическую функцию правдоподобия 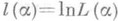 ; в силу монотонности логарифма точки максимумов функций L(a).и l(a) совпадают). Примерами О. с. максимального правдоподобия являются оценки по наименьших квадратов методу.
; в силу монотонности логарифма точки максимумов функций L(a).и l(a) совпадают). Примерами О. с. максимального правдоподобия являются оценки по наименьших квадратов методу.
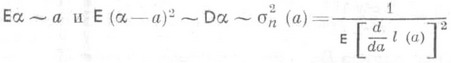
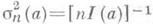 ). Таким образом, для функции распределения нормированной О. с.
). Таким образом, для функции распределения нормированной О. с. 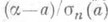 имеет место предельное соотношение
имеет место предельное соотношение 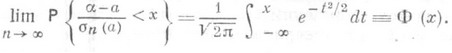 (8)
(8) независимы и распределены одинаково нормально так, что
независимы и распределены одинаково нормально так, что 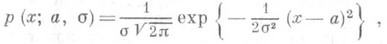
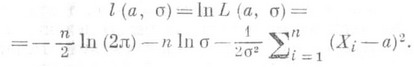
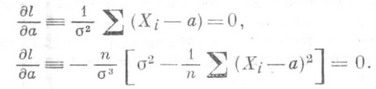
 и, значит, в данном случае О. с. (1) и (2) - оценки максимального правдоподобия, причем
и, значит, в данном случае О. с. (1) и (2) - оценки максимального правдоподобия, причем 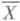 - наилучшая О. с. параметра а, распределенная нормально (
- наилучшая О. с. параметра а, распределенная нормально (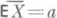 ,
, 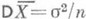 ), а
), а 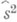 - асимптотически эффективная О. с. параметра s2, распределенная при больших пприближенно нормально (
- асимптотически эффективная О. с. параметра s2, распределенная при больших пприближенно нормально (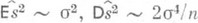 ). Обе оценки представляют собой независимые достаточные статистики.
). Обе оценки представляют собой независимые достаточные статистики.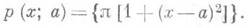
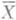 распределено в данном случае с той же плотностью р(х; a), что и каждый единичный результат наблюдений. Для оценки аможно воспользоваться тем обстоятельством, что рассматриваемое распределение симметрично относительно точки х=а и, значит, а - медиана теоретич. распределения. Несколько видоизменяя метод моментов, в качестве О. с. для апринимают т. н. выборочную медиану m, к-рая при
распределено в данном случае с той же плотностью р(х; a), что и каждый единичный результат наблюдений. Для оценки аможно воспользоваться тем обстоятельством, что рассматриваемое распределение симметрично относительно точки х=а и, значит, а - медиана теоретич. распределения. Несколько видоизменяя метод моментов, в качестве О. с. для апринимают т. н. выборочную медиану m, к-рая при  является несмещенной О. с. для a, причем если пвелико, то m распределена приближенно нормально с дисперсией
является несмещенной О. с. для a, причем если пвелико, то m распределена приближенно нормально с дисперсией 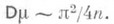

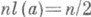 и, значит, согласно (7) асимптотич. эффективность
и, значит, согласно (7) асимптотич. эффективность 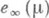 равна
равна  . Таким образом, для того чтобы выборочная медиана m была столь же точной О. с. для a, как и оценка наибольшего правдоподобия a, нужно количество наблюдений увеличить на 25%. Если затраты на эксперимент велики, то для определения аследует воспользоваться О. с. а, к-рая в данном случае определяется как корень уравнения
. Таким образом, для того чтобы выборочная медиана m была столь же точной О. с. для a, как и оценка наибольшего правдоподобия a, нужно количество наблюдений увеличить на 25%. Если затраты на эксперимент велики, то для определения аследует воспользоваться О. с. а, к-рая в данном случае определяется как корень уравнения 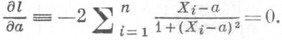
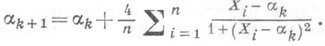
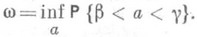
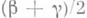 принять за точечную О. с. для параметра a, то с вероятностью не менее чем со можно утверждать, что абсолютная погрешность этой О. с. не превышает половины длины интервала
принять за точечную О. с. для параметра a, то с вероятностью не менее чем со можно утверждать, что абсолютная погрешность этой О. с. не превышает половины длины интервала 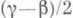 . Иными словами, если руководствоваться указанным правилом оценки абсолютной погрешности, то ошибочное заключение будет получаться в среднем менее чем в
. Иными словами, если руководствоваться указанным правилом оценки абсолютной погрешности, то ошибочное заключение будет получаться в среднем менее чем в  случаев. При фиксированном коэффициенте доверия со наиболее выгодны кратчайшие доверительные интервалы, для к-рых математич. ожидание длины
случаев. При фиксированном коэффициенте доверия со наиболее выгодны кратчайшие доверительные интервалы, для к-рых математич. ожидание длины 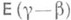 достигает наименьшего значения.
достигает наименьшего значения.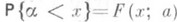 разумно выбранной О. с. а монотонно зависит от параметра а. В этих условиях для отыскания интервальной О. с. следует в F(х; а )подставить х=a. и определить корни а 1= a1(a, w) и а 2=a2(a, w) уравнений
разумно выбранной О. с. а монотонно зависит от параметра а. В этих условиях для отыскания интервальной О. с. следует в F(х; а )подставить х=a. и определить корни а 1= a1(a, w) и а 2=a2(a, w) уравнений 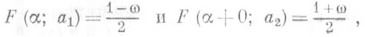 (9) где
(9) где 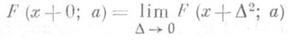
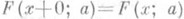 ]. Точки с координатами
]. Точки с координатами 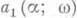 и
и 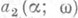 ограничивают доверительный интервал с коэффициентом доверия w. Разумеется, интервал, построенный столь простым способом, во многих случаях может отличаться от оптимального (кратчайшего). Однако если a - асимптотически эффективная О. с. для a, то при достаточно большом количестве наблюдений такая интервальная О. с. практически несущественно отличается от оптимальной. В частности, это верно для О. с. наибольшего правдоподобия, т. к. она распределена асимптотически нормально (см. (8)). В тех случаях, когда решение уравнений (9) затруднительно, интервальную О. с. вычисляют приближенно с помощью точечной О. с. максимального правдоподобия и соотношения (8):
ограничивают доверительный интервал с коэффициентом доверия w. Разумеется, интервал, построенный столь простым способом, во многих случаях может отличаться от оптимального (кратчайшего). Однако если a - асимптотически эффективная О. с. для a, то при достаточно большом количестве наблюдений такая интервальная О. с. практически несущественно отличается от оптимальной. В частности, это верно для О. с. наибольшего правдоподобия, т. к. она распределена асимптотически нормально (см. (8)). В тех случаях, когда решение уравнений (9) затруднительно, интервальную О. с. вычисляют приближенно с помощью точечной О. с. максимального правдоподобия и соотношения (8):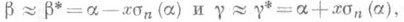
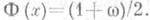
 , то истинный коэффициент доверия интервальной оценки
, то истинный коэффициент доверия интервальной оценки 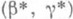 стремится к w. В более общем случае распределение результатов наблюдений Xi - зависит от нескольких параметров а, b,.... В этих условиях указанные выше правила построения доверительных интервалов часто оказываются неприменимыми, т. к. распределение точечной О. с. a, зависит, как правило, не только от a, но и от остальных параметров. Однако в практически интересных случаях О. с. a можно заменить такой функцией от результатов наблюдений Xi и неизвестного параметра я, распределение к-рой не зависит (или "почти не зависит") от всех неизвестных параметров. Примером такой функции может служить нормированная О. с. максимального правдоподобия
стремится к w. В более общем случае распределение результатов наблюдений Xi - зависит от нескольких параметров а, b,.... В этих условиях указанные выше правила построения доверительных интервалов часто оказываются неприменимыми, т. к. распределение точечной О. с. a, зависит, как правило, не только от a, но и от остальных параметров. Однако в практически интересных случаях О. с. a можно заменить такой функцией от результатов наблюдений Xi и неизвестного параметра я, распределение к-рой не зависит (или "почти не зависит") от всех неизвестных параметров. Примером такой функции может служить нормированная О. с. максимального правдоподобия 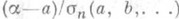 ; если в знаменателе аргументы a, b,... заменить их оценками максимального правдоподобия a, b,. . . , то предельное распределение останется тем же самым, что и в формуле (8). Поэтому приближенные доверительные интервалы для каждого параметра в отдельности можно строить так же, как и в случае одного параметра.
; если в знаменателе аргументы a, b,... заменить их оценками максимального правдоподобия a, b,. . . , то предельное распределение останется тем же самым, что и в формуле (8). Поэтому приближенные доверительные интервалы для каждого параметра в отдельности можно строить так же, как и в случае одного параметра.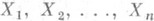 ,... - независимые и одинаково нормально распределенные случайные величины, то
,... - независимые и одинаково нормально распределенные случайные величины, то 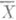 и s2 - наилучшие О. с. для параметров a и s2 соответственно. Функция распределения О. с. выражается формулой
и s2 - наилучшие О. с. для параметров a и s2 соответственно. Функция распределения О. с. выражается формулой 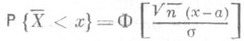
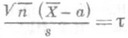
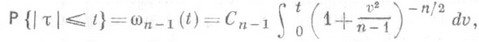
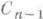 выбирается так, чтобы выполнялось равенство
выбирается так, чтобы выполнялось равенство 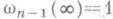 . Таким образом, доверительному интервалу
. Таким образом, доверительному интервалу 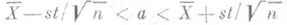
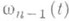
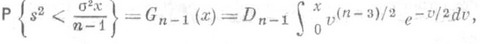
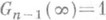 (так наз.
(так наз. 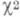 -распределением с п-1степенями свободы).
-распределением с п-1степенями свободы).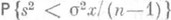 монотонно возрастает, то для построения интервальной О. с. применимо правило (9). Таким образом, если х 1 и x2 - корни уравнений
монотонно возрастает, то для построения интервальной О. с. применимо правило (9). Таким образом, если х 1 и x2 - корни уравнений 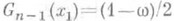 и
и 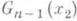 =
=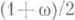 , то доверительному интервалу
, то доверительному интервалу 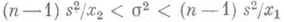

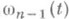 и
и 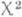 -распределения
-распределения 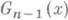 имеются в большинстве руководств по математич. статистике.
имеются в большинстве руководств по математич. статистике.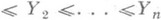 - те же величины Xi но расположенные в порядке возрастания. Тогда, если k - целое число, удовлетворяющее неравенствам
- те же величины Xi но расположенные в порядке возрастания. Тогда, если k - целое число, удовлетворяющее неравенствам  n/2, то
n/2, то 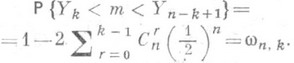
 - интервальная О. с. для тс коэффициентом доверия w=wn,k. Этот вывод верен при любом непрерывном распределении случайных величин Xi.
- интервальная О. с. для тс коэффициентом доверия w=wn,k. Этот вывод верен при любом непрерывном распределении случайных величин Xi.
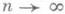 стремится к предельному распределению К(у), к-рое наз. распределением Колмогорова. Таким образом, если у - решение уравнения К(y)=w, то с вероятностью w можно утверждать, что график функции теоретич. распределения F(у).целиком "покрывается" полосой, заключенной между графиками функций
стремится к предельному распределению К(у), к-рое наз. распределением Колмогорова. Таким образом, если у - решение уравнения К(y)=w, то с вероятностью w можно утверждать, что график функции теоретич. распределения F(у).целиком "покрывается" полосой, заключенной между графиками функций 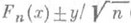 (при
(при  различие допредельного и предельного распределений статистики ln практически несущественно). Такую интервальную О. с. наз. доверительной зоной. См. также Интервальная оценка.
различие допредельного и предельного распределений статистики ln практически несущественно). Такую интервальную О. с. наз. доверительной зоной. См. также Интервальная оценка. . Таким образом, если приведено пнезависимых измерений величины a, то их результаты можно записать в виде равенств
. Таким образом, если приведено пнезависимых измерений величины a, то их результаты можно записать в виде равенств 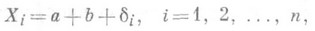 (10)
(10)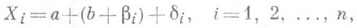 (11)
(11)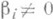 маловероятно). Величину bi наз. грубой ошибкой.
маловероятно). Величину bi наз. грубой ошибкой.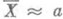 и
и  (см. (1) и (2)). Если di распределены одинаково нормально, то эти О. с. наилучшие; в других случаях эти оценки могут оказаться малоэффективными.
(см. (1) и (2)). Если di распределены одинаково нормально, то эти О. с. наилучшие; в других случаях эти оценки могут оказаться малоэффективными. бывает невелика, а математич. ожидание ненулевых |bi| значительно превышает
бывает невелика, а математич. ожидание ненулевых |bi| значительно превышает 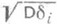 (грубые ошибки возникают в результате случайного просчета, неправильного чтения показаний измерительного прибора и т. п.). Результаты измерений, содержащие грубые ошибки, часто бывают хорошо заметны, т. к. они сильно отличаются от других результатов измерений. В этих условиях наиболее целесообразный способ выявления (и устранения) грубых ошибок - непосредственный анализ измерений, тщательная проверка неизменности условий всех экспериментов, запись результатов "в две руки" и т. д. Статистич. методы выявления грубых ошибок следует применять лишь в сомнительных случаях.
(грубые ошибки возникают в результате случайного просчета, неправильного чтения показаний измерительного прибора и т. п.). Результаты измерений, содержащие грубые ошибки, часто бывают хорошо заметны, т. к. они сильно отличаются от других результатов измерений. В этих условиях наиболее целесообразный способ выявления (и устранения) грубых ошибок - непосредственный анализ измерений, тщательная проверка неизменности условий всех экспериментов, запись результатов "в две руки" и т. д. Статистич. методы выявления грубых ошибок следует применять лишь в сомнительных случаях.
 вычисляются по всем пнаблюдениям согласно формулам (1) и (2)). Для больших значений
вычисляются по всем пнаблюдениям согласно формулам (1) и (2)). Для больших значений 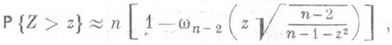
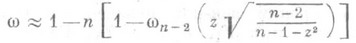 (12)
(12)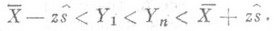
 то нет оснований считать какое-нибудь измерение содержащим грубую ошибку.
то нет оснований считать какое-нибудь измерение содержащим грубую ошибку.