|
"
0
C
F
G
H
K
L
N
P
S
T
W
Z
А
Б
В
Г
Д
Е
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Э
Ю
Я
ДИСКРИМИНАНТНЫЙ АНАЛИЗЗначение ДИСКРИМИНАНТНЫЙ АНАЛИЗ в математической энциклопедии: - раздел математич. статистики, содержанием к-рого является разработка и исследование статистич. методов решения следующей задачи различения (дискриминации): основываясь на результатах наблюдений", определить, какой из нескольких возможных совокупностей принадлежит объект, случайно извлеченный из одной из них. На практике задача различения возникает, напр., в тех случаях, когда наблюдение признака, полностью определяющего принадлежность объекта к той или иной совокупности, невозможно или требует чрезмерных затрат средств или времени; в случаях, когда информация о таком признаке утеряна, и ее нужно восстановить, а также, когда речь идет о предсказании будущих событий на основе имеющихся данных. Ситуации первого типа встречаются в медицинской практике, напр, при установлении диагноза по комплексу неспецифических проявлений заболевания. Пример ситуации второго типа - определение пола давно умершего человека по останкам, найденным при археологич. раскопках. Ситуация третьего типа возникает, напр., при статистич. прогнозе отдаленных результатов лечения. Методом Д. а. является многомерный статистический анализ, служащий для количественного выражения и обработки имеющейся информации в соответствии с выбранным критерием оптимальности решения. В общем виде задача различения ставится следующим образом. Пусть результатом наблюдения над случайным объектом является реализация р-мерного случайного вектора х' =( х 1, ..., х р )(штрих означает транспонирование) значений рпризнаков объекта. Требуется установить правило, согласно к-рому по значению вектора х объект относят к одной из возможных совокупностей pi, i=1, ... , k. Построение правила дискриминации состоит в том, что все выборочное пространство R значений вектора хразбивается на области Ri, i=l, ... , k, так что при попадании х в Ri объект относят к совокупности pi. Выбор правила дискриминации среди всех возможных производится в соответствии с установленным принципом оптимальности на основе априорной информации о совокупностях pi и вероятностях qi извлечения объекта из pi. При этом учитывается размер убытка от неправильной дискриминации. Априорная информация о совокупностях pi может состоять в том, что известны функции распределения вектора признаков объекта в каждой из этих совокупностей, она может быть представлена также и в виде выборок из каждой из этих совокупностей, при этом априорные вероятности qi совокупностей могут быть либо известны, либо нет. Очевидно, чем полнее исходная информация, тем точнее могут быть рекомендации. Пусть рассматривается случай двух совокупностей p1 и p2 в ситуации, когда имеется полная исходная информация: известны функции распределения вектора признаков в каждой из совокупностей и априорные вероятности (бейесовский подход). Пусть Р 1 (х)и Р 2 (х)- функции распределения вектора признаков соответственно в p1 и p2, p1(x)и р 2 (х) - плотности распределения, a C(i|i), i, j=1,2,- убыток вследствие отнесения объекта из j -й совокупности к i-й. Тогда вероятности неправильной дискриминации объектов из p1 и p2 соответственно равны:
(символом P(i|j; R )обозначена вероятность приписывания объекта из pj к совокупности pi при использовании правила R), а математич. ожидание потерь, связанных с неверной дискриминацией, равно
Естественным в рассматриваемой ситуации принципом оптимальности является принцип минимизации этой величины, к-рый приводит в этом случае к следующему разбиению пространства выборок [1]:
Если выполнены условия
то такое разбиение единственно с точностью до множества нулевой вероятности. К аналогичному правилу различения в рассмотренном случае можно прийти и другими путями, напр. с помощью Неймана- Пирсона леммы из теории проверки статистич. гипотез. При выбранном критерии оптимальности о качестве правила различения судят по величине математич. ожидания потерь, и из двух правил лучшим считается то, к-рое приводит к меньшему значению этой величины. Если в задаче различения априорные вероятности qi неизвестны, то естественно искать решение в классе допустимых правил, выбирая среди них правило, минимизирующее максимум по всем qi математич. ожидания потерь (такое правило наз. минимаксным). Математич. ожидания потерь при условии, что наблюдения производились соответственно над объектами из p1 или p2, равны
Справедливо утверждение (см. [1]): если выполнены условия
то класс бейесовских методов является минимальным полным классом. Минимаксное правило R* из этого класса получается при значении q1, для к-рого выполнено условие P(2|1; R*) = P(1/2; R*). В важном случае, когда Р 1 и Р 2 - многомерные нормальные распределения с векторами средних m(1) и m(2) и общей ковариационной матрицей 2, правило дискриминации (1) принимает вид:
где
Если априорные вероятности неизвестны, то можно выбрать ln k=c, напр, из условия минимальности ошибки неверной дискриминации или из условия обращения в нуль математич. ожидания потерь от неверной дискриминации. Вообще говоря, выбор критерия оптимальности, как правило, определяется характером самой задачи. Выражение в левой части (3) наз. дискриминантной функцией данной задачи; ее можно толковать как поверхность в выборочном пространстве, разделяющую совокупности p1. и p2. В приведенном примере дискриминантная функция линейна, т. е. такая поверхность есть гиперплоскость. Если в приведенном примере матрицы ковариации неодинаковы, то дискриминантная функция будет квадратичной функцией от х. В целях упрощения вычислений найден минимальный полный класс линейных процедур различения для этого случая (см. [3]). С точки зрения применений Д. а. наиболее важной является ситуация, когда исходная информация о распределениях ' представлена выборками из них. В этом случае задача дискриминации ставится следующим образом. Пусть х 1(i), х 2(i), . .., х n(i)- выборка из совокупности pi, Наиболее изученным является случай, когда известно, что распределения векторов признаков в каждой совокупности нормальны, но нет информации о параметрах этих распределений. Здесь самым естественным является подход, состоящий в замене неизвестных параметров распределений в дискриминантной функции (3) их наилучшими оценками (см. [5], [6]). Как и в случае известных распределений, правило дискриминации можно основывать на отношении правдоподобия (см. [7], [8]). Подавляющая часть результатов Д. а. получена в предположении нормальности распределений. Изучаются вопросы применимости оптимальных в нормальном случае методов в ситуациях, где предположение о нормальности носит лишь приближенный характер [9]. В этих работах задачи Д. а. рассматриваются в рамках общей теории решающих функций и изучаются свойства правил дискриминации по отношению к так наз. принципу Q-оптимальности, естественным образом охватывающему как бейесовский, так и минимаксный подходы. Именно, пусть R(x, d) - вероятность ошибки при применении правила дискриминации б, когда вектор априорных вероятностей есть x. Пусть известно, что
где D- множество всех возможных правил дискриминации. Пусть известен функциональный вид Р i( х, li), зависящих от параметра распределений вектора признаков в каждой из совокупностей, i=1, 2, но параметр l неизвестен и оценивается по выборке. Тогда если Pi( х,li) таковы, что существует Q-оптимальное правило d*(l1, l2) дискриминации для распределений Pi(x,li), i=l, 2, когда значение параметра l=(l1, l2) известно, и {li(ni) } - сильно состоятельная оценка параметра li по выборке объема ni, то при нек-рых дополнительных условиях последовательность правил {d*(li(n1), li(n2))} при
где риск Rв левой части (5) может быть вычислен как при истинном значении параметров, так и при замене истинных значений их оценками li(ni) . Если потребовать лишь состоятельности оценки, то имеет место несколько более слабое утверждение. Непараметрич. методы дискриминации, не требующие знаний о точном функциональном виде распределений и позволяющие решать задачи дискриминации на основе малой априорной информации о совокупностях, являются особо ценными для практических применений [2], [10]. В задачах Д. а. приходится иметь дело со случайными наблюдениями как над количественными, так и над качественными признаками (возможен и смешанный случай). Между этими случаями нет принципиальной разницы. Если признаки качественные, то вводится понятие многомерного состояния объекта и рассматривается распределение по нему. От природы наблюдений зависит способ оценки функции распределений вектора признаков. В соответствующих ситуациях снова применимы бейесовский и минимаксный подходы и можно строить процедуру различения, основываясь на отношении правдоподобия. Иногда целесообразно переходить от количественных величин к качественным путем разбиения функции частот, и наоборот, от качественных к количественным, вводя фиктивные переменные, преобразующие качественную информацию в количественную. При этом, разумеется, нужно исследовать вопрос о том, не происходит ли существенного ухудшения качества правила. Выше рассматривались задачи Д. а. при фиксированной размерности пространства значений вектора признаков. Однако практич. ситуации чаще всего таковы, что выбор размерности осуществляется исследователем. На первый взгляд кажется, что добавление каждого нового признака в дискриминантной функции по крайней мере не ухудшит ее качества. Однако многие факторы могут при этом вести к потере эффективности различения (достаточно вспомнить, что вместо истинных значений параметров распределений часто используются их оценки). К тому же увеличение числа признаков ведет к быстрому возрастанию трудностей счета. Имеется много рекомендаций для выбора признаков, диктуемых часто здравым смыслом. Теоретически наиболее обоснованным методом выбора признаков является метод, основанный на вычислении расстояния Махаланобиса между двумя распределениями [11]. Особый интерес представляют последовательные методы выбора признаков. Долгое время задачи отнесения объекта к одной из нескольких возможных совокупностей носили общее название задач классификации. Здесь приведена терминология Кендалла [2], разделившего все задачи, связанные с выбором одной из нескольких равноправных возможностей на три класса. Он назвал задачи рассматриваемого здесь вида задачами различения (дискриминации), оставив термин "классификация" для задач разбиения данной выборки или всей совокупности на группы, по возможности однородные. Если в задачах различения существование групп оговорено в условиях, то здесь это - предмет исследования. Выше были рассмотрены задачи различения, когда исследуемый объект есть результат случайного выбора из нек-рого конечномерного распределения. Возможна более общая ситуация, когда исследуемый объект представляет собой реализацию нек-рого случайного процесса с непрерывным временем. Д. а. тесно связан также с теорией распознавания образов. Лит.:[1] Андерсон Т., Введение в многомерный статистический анализ, пер. с англ., М., 1963; [2] Kendall М. G., Stuart A., The advanced theory of statistics, v. 3, L., 1966; [3] Andersоn T. W., Вahadur R. R., "Ann. Math. Statistics", 1962, v. 33, Jsfi 2, p. 420-31; [4] Fisсher R. A., "Ann. Eugenics", 1936, v. 7, № 11, p. 179-188; [5] Wald A., "Ann. Math. Statistics", 1944, v. 15, № 2, p. 145-62; [6] JohnS., "Sankhya", 1960, v. 22, pt. 3-4, p. 301 - 16; [7] Welch B. L., "Biometrika", 1939, v. 31, pt. 1-2, p. 218- 220; [8] Gupta S. D., "Ann. Math. Statistics", 1965, v. 36, J* 4, p. 1174-84; [9] Bunke O., "Z. Wahrscheinlichkeitstheor. und verw. Geb.", 1967, Bd 7, № 2, S. 131 - 46; [10] Rуzin J. van, "Sankhya", ser. A, 1966, v. 28, pt. 2-3, p. 261-70; [11] Kudo A., "Memoirs of the Faculty of Science. Kyushu Univ.", ser. A, 1963, v. 17, №1, p. 63-75; [12] Уpбax В. Ю., в сб.: Статистические методы классификации, в. 1, М., 1969, с. 79- 173 (лит.). Н. М. Митрофанова, А. П. Хусу. |
|
|
|
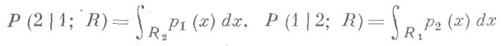






 Если С(1|2)=С(2|1) и q2=qu то ln k=0
Если С(1|2)=С(2|1) и q2=qu то ln k=0
 - вектор признаков /-го объекта выборки из г-й совокупности, и произведено дополнительное наблюдение х' =( х 1, ..., х р )над объектом, принадлежащим одной из совокупностей pi. Требуется построить правило приписывания наблюдения хк одной из этих совокупностей. Первый подход к решению этой задачи в случае двух совокупностей принадлежит Р. А. Фишеру - основоположнику Д. а. [4]. Используя в задаче различения вместо вектора признаков, характеризующих объект, их линейную комбинацию - гиперплоскость, в нек-ром смысле наилучшим образом разделяющую совокупность выборочных точек,- он пришел к дискриминантной функции (3).
- вектор признаков /-го объекта выборки из г-й совокупности, и произведено дополнительное наблюдение х' =( х 1, ..., х р )над объектом, принадлежащим одной из совокупностей pi. Требуется построить правило приписывания наблюдения хк одной из этих совокупностей. Первый подход к решению этой задачи в случае двух совокупностей принадлежит Р. А. Фишеру - основоположнику Д. а. [4]. Используя в задаче различения вместо вектора признаков, характеризующих объект, их линейную комбинацию - гиперплоскость, в нек-ром смысле наилучшим образом разделяющую совокупность выборочных точек,- он пришел к дискриминантной функции (3). где Q- некоторое множество в пространстве векторов x. Правило d* наз. Q-оптимальным, если
где Q- некоторое множество в пространстве векторов x. Правило d* наз. Q-оптимальным, если
 является асимптотически оптимальной, то есть с вероятностью 1
является асимптотически оптимальной, то есть с вероятностью 1